{benchmarkme}: new version
When discussing how to speed up slow R code, my first question is what is your computer spec? It’s always surprised me that people are wondering why analysing big data is slow, yet they are using a five-year-old cheap laptop. Spending a few thousand pounds would often make their problems disappear. To quantify the impact of the CPU on analysis, I created the package {benchmarkme}. The aim of this package is to provide a set of benchmarks routines and data from past runs. You can then compare your machine, with other CPUs.
The package is now on CRAN and can be installed in the usual way
# R 3.5.X only
install.packages("benchmarkme")
The benchmark_std() function assesses numerical operations such as loops and matrix operations. This benchmark contains two main benchmarks
benchmark_std(): this benchmarks numerical operations such as loops and matrix operations. The benchmark comprises three separate benchmarks:prog,matrix_fun, andmatrix_cal.benchmark_io(): this benchmarks reading and writing a 5 / 50, MB CSV file.
The benchmark_std() function
This benchmarks numerical operations such as loops and matrix operations. This benchmark comprises three separate benchmarks: prog, matrix_fun, and matrix_cal.
If you have less than 3GB of RAM (run get_ram() to find out how much is available on your system), then you should kill any memory hungry applications, e.g. Firefox, and set runs = 1 as an argument.
To benchmark your system, use
library("benchmarkme")
## Increase runs if you have a higher spec machine
res = benchmark_std(runs = 3)
and upload your results
## You can control exactly what is uploaded. See details below.
upload_results(res)
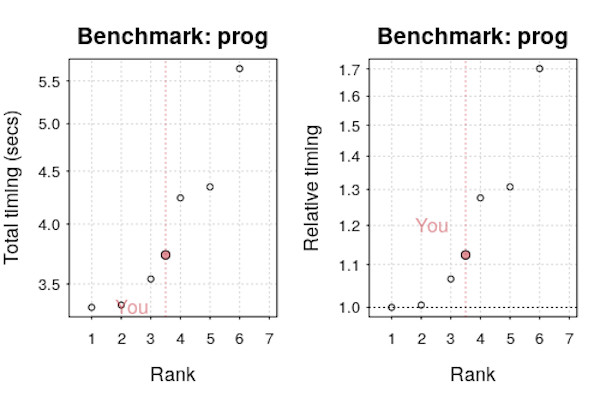
You can compare your results to other users via
plot(res)

The benchmark_io() function
This function benchmarks reading and writing a 5MB or 50MB (if you have less than 4GB of RAM, reduce the number of runs to 1). Run the benchmark using
res_io = benchmark_io(runs = 3)
upload_results(res_io)
plot(res_io)
By default, the files are written to a temporary directory generated
tempdir()
which depends on the value of
Sys.getenv("TMPDIR")
You can alter this to via the tmpdir argument. This is useful for comparing hard drive access to a network drive.
res_io = benchmark_io(tmpdir = "some_other_directory")
As before, you can compare your results to previous results via
plot(res_io)
Parallel benchmarks
The benchmark functions above have a parallel option - just simply specify the number of cores you want to test. For example to test using four cores
res_io = benchmark_std(runs = 3, cores = 4)
Previous versions of the package
This package was started around 2015. However, multiple changes in the byte compiler over the last few years has made it very difficult to use previous results. Essentially, the detecting if and how the byte compiler was being used became near on impossible. Also, R has just “got faster”, so it doesn’t make sense to compare benchmarks between different R versions. So we have to start from scratch (I did spend a few days trying to salvage something but to no avail).
The previous data can be obtained via
data(past_results, package = "benchmarkmeData")
Machine specs
The package has a few useful functions for extracting system specs:
- RAM:
get_ram() - CPUs:
get_cpu() - BLAS library:
get_linear_algebra() - Is byte compiling enabled:
get_byte_compiler() - General platform info:
get_platform_info() - R version:
get_r_version()
The above functions have been tested on a number of systems. If they don’t work on your system, please raise GitHub issue.
Uploaded datasets
A summary of the uploaded datasets is available in the benchmarkmeData package
data(past_results_v2, package = "benchmarkmeData")
A column of this data set contains the unique identifier returned by the upload_results() function.
What’s uploaded
Two objects are uploaded:
- Your benchmarks from
benchmark_stdorbenchmark_io; - A summary of your system information (
get_sys_details()).
The get_sys_details() returns:
Sys.info();get_platform_info();get_r_version();get_ram();get_cpu();get_byte_compiler();get_linear_algebra();installed.packages();Sys.getlocale();- The
benchmarkmeversion number; - Unique ID - used to extract results;
- The current date.
The function Sys.info() does include the user and nodenames. In the public release of the data, this information will be removed. If you don’t wish to upload certain information, just set the corresponding argument, i.e.
upload_results(res, args = list(sys_info = FALSE))