{benchmarkme}: new version
Published: January 29, 2019.
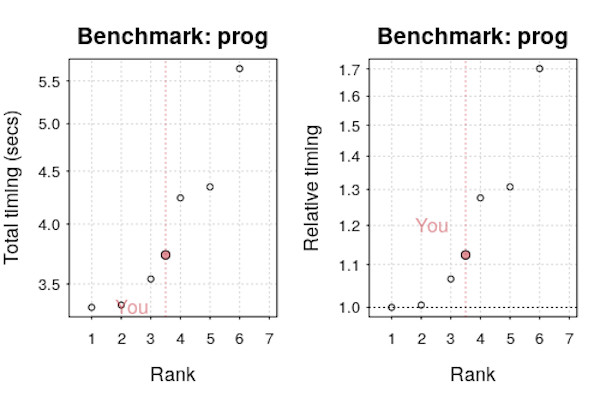
When discussing how to speed up slow R code, my first question is what is your computer spec? It’s always surprised me that people are wondering why analysing big data is slow, yet they are using a five-year-old cheap laptop. Spending a few thousand pounds would often make their problems disappear.