Why learn the command-line interface?
Published: July 30, 2026.
In this blog post we outline some reasons why it is valuable to learn how to use the command line as a data scientist.
Published: July 30, 2026.
In this blog post we outline some reasons why it is valuable to learn how to use the command line as a data scientist.
Published: July 16, 2026.
Using a sample flight-departures dashboard, we walk through five things that are easy to miss before launch: responsive layout, touchscreen support, accessibility, and both real and perceived performance.

Published: June 25, 2026.
Jumping Rivers recently hosted the conference "AI In Production 2026" where experts across software engineering and data science discussed how to actually use AI in software products and data projects. The talks also touched on security, regulatory matters, AI usage across different sectors and how AI has impacted the process of software development. Here we summarise the conference talks. "AI In Production 2027" will be held 10-11 June 2027.

Published: May 28, 2026.
Some thoughts on learning to use Claude to write Bash shell scripts and improve my productivity.

Published: April 14, 2026.
Learn how to work with Large Language Models programmatically in R and Python, from sending API requests to generating structured outputs and summarising content.

Published: March 19, 2026.
Teams may need a way to reliably generate datasets and data products from newly-collected raw data that is robust to the evolution of both the team and the raw data. This is where 'Reproducible Analytical Pipelines' (RAPs) can help.

Published: March 12, 2026.
Introducing the Frontend Dashboard Health Check!

Published: March 5, 2026.
Join our free webinar exploring data processing workflows in pandas and polars, comparing syntax, performance considerations, and updates introduced in pandas 3.0.

Published: December 8, 2025.
Level up your Shiny skills with Jumping Rivers’ free 55-minute accessibility webinars, designed to help you build inclusive, professional apps that work for everyone. Join the community, learn practical techniques, and unlock exclusive discounts when you register.

Published: December 4, 2025.
"In part three of this blog series, I am going to improve the efficiency of the function written in part one using parallisation."

Published: November 27, 2025.
Start 2026 strong with Jumping Rivers’ hands-on online training courses, designed to boost your skills, confidence, and career prospects in just a few focused hours.

Published: November 19, 2025.
Registration is open for the first AI in Production conference, taking place in Newcastle Upon Tyne on 4 and 5 June 2026.

Published: November 17, 2025.
Stay ahead of the curve with Jumping Rivers’ next free monthly webinar, 'Machine Learning with Python', where you’ll level up your data skills in just 55 minutes and unlock exclusive learning perks.

Published: November 13, 2025.
Did you know that we organise free, in-person data science meetups? In this post we will talk through the typical format and topics at our meetups, along with some details for how you can get involved!

Published: November 6, 2025.
Here we compare the syntax of two Python libraries, Pandas and Polars for standard data-manipulation tasks.

Published: November 3, 2025.
This October, Jumping Rivers hosted the fourth installment of our conference "Shiny In Production". Here we summarise the talks and workshops that were presented.

Published: October 28, 2025.
Boost your data expertise with hands-on, expert-led training from Jumping Rivers. Our experienced data scientists deliver practical courses in R, Python, Git, AI, and more, designed to help you apply new skills immediately. With flexible online and in-person options, comprehensive materials, and tailored in-house programmes, Jumping Rivers empowers individuals and teams to thrive in today’s data-driven world.

Published: October 16, 2025.
Python 3.14 was released in October. Here we summarise some of the more interesting changes and some trends in Python development and data-science over the past year.

Published: October 13, 2025.
Join our free Jumping Rivers webinar, “Understanding Posit: Ecosystem and Use Cases,” to discover how Posit tools like Connect, Workbench, and Package Manager can power scalable, collaborative data workflows.

Published: September 15, 2025.
Our free monthly webinar series is back, and the first session on 21 August – “Reports that Write Themselves: Automated Reporting with Quarto” was a fantastic success! It was wonderful to see the Jumping Rivers community grow, with so many data professionals joining, engaging, and sharing ideas.

Published: September 9, 2025.
At Jumping Rivers, we streamline data workflows with engineering, automation, and analytics. We handle the tasks you can’t, optimise the ones you didn’t know could be improved, and work alongside your team to make operations easier, smarter, and faster.

Published: August 28, 2025.
We introduce the ARIMA framework for time series forecasting and demonstrate the process using a real world example with Python. Along the way we explore the time series analysis functions provided by the statsmodels library and cover best practices for selecting the ARIMA model parameters.

Published: August 12, 2025.
When it comes to data science training, one size doesn’t fit all. At Jumping Rivers, we’ve built our reputation around delivering customised, expert-led training that actually fits your team’s goals, tools, and workflows - whether you're in healthcare, government, finance, or beyond.

Published: August 5, 2025.
Shiny in Production Conference is fast approaching and we wouldn't be able to put it on without the support of our sponsors!

Published: July 17, 2025.
Importing data is a key step in the data science workflow. How you import a dataset has consequences for how you work with that data throughout a project.

Published: July 8, 2025.
Are you ready to expand your knowledge in R, Python, Shiny, and Posit while becoming a more valuable asset to your team? Jumping Rivers is here to help you do just that with our free monthly webinar series designed for data professionals at all levels.

Published: June 24, 2025.
We are pleased to announce the lightning talks for this year's Shiny in Production conference! In this blog post, we've pulled together all of the talk abstracts to give you a full view of what to expect!

Published: June 17, 2025.
We are pleased to announce the full length talks for this year's Shiny in Production conference! In this blog post, we've pulled together all of the talk abstracts to give you a full view of what to expect!

Published: June 9, 2025.
At Jumping Rivers, we believe training should be more than just a tick-box exercise. It should be transformative. Whether you’re learning R, Python, SQL, Git or Posit for the first time or diving into advanced topics like machine learning and Quarto, our courses are built to help you actually use what you learn — not just watch someone code.

Published: June 5, 2025.
Adding images to a web page used to be easy. Now with high-resolution screens and an array of modern image formats it can feel like much more work. This post explains why things have become more complex and suggestions solutions for making life a little easier and web pages more performant.

Published: May 20, 2025.
The details of all of our workshops for Shiny in Production are now live on the conference website. Read on for full details all in one place.

Published: May 8, 2025.
Writing tests is one of the best ways to keep your Python code reliable and reproducible. This post builds on our previous blog about Python testing with pytest, and explores some of the more advanced features it offers. We will show how to make your tests more reproducible, easier to manage and demonstrate how writing simple tests can save you time in the long run.

Published: April 15, 2025.
At Jumping Rivers we love data dashboards and are delighted to announce the release of a gallery to showcase our application-development skills.

Published: March 11, 2025.
Due to popular demand we are extending the abstract deadline for Shiny in Production 2025, to be held on 8th-9th October 2025 in Newcastle upon Tyne, UK. Read on for more details on how to submit your work.

Published: February 27, 2025.
Part 4 of our series of blogs on vetiver for MLOps. Having previously explained how to set up an MLOps workflow in R, we now turn to Python. This blog will introduce the vetiver package for Python and outline the key MLOps steps including model versioning, deployment and monitoring.

Published: February 17, 2025.
We are excited to announce the Call for Abstracts for Shiny in Production 2025, to be held on 8th-9th October 2025 in Newcastle upon Tyne, UK. Read on for more details on how to submit your work.

Published: January 30, 2025.
This post, Part 2 in a series of two, looks at styling and deploying the Observable Framework app we built in part 1.
Published: January 23, 2025.
The fourth instalment of Shiny in Production is back this October, hosted at the Catalyst in Newcastle upon Tyne, with super early bird tickets deadline for Shiny in Production ends on the 31st of January.

Published: January 16, 2025.
This post, Part 1 in a series of two, looks at porting the functional code of a Shiny app - written in R - into JavaScript code to be used in an Observable Framework application.

Published: December 12, 2024.
The latest version of Posit Package Manager allows us to add metadata to package pages. This means we can now directly link R and Python packages to diffify.com!

Published: November 7, 2024.
All of our public training courses for the first half of 2025 are now available to book! Head over to our public training webpage to book in and start building your programming skills in the new year! In this blog, we list all of our upcoming courses with a description, bookable dates, course level and a link to find out more.

Published: September 5, 2024.
Programming is a craft, and in data science we often spend countless hours coding. Software testing can improve the quality of the code you write as a data scientist. Here, we introduce the pytest framework and show how it can be used to test Python functions.

Published: August 8, 2024.
We are pleased to announce the full line-up for this year's Shiny in Production conference! In this blog post, we've pulled together all of the talk abstracts to give you a full view of what to expect!

Published: July 4, 2024.
The details of all of our workshops for Shiny in Production are now live on the conference website. Read on for full details all in one place.

Published: June 6, 2024.
Our courses for the second half of 2024 have now been released. We have everything from the very basics of R and Python for data science, to advanced statistical modelling and machine learning. Interested in dashboards and reporting? We have courses on reporting with Quarto, as well as both introductory and advanced Shiny.

Published: May 30, 2024.
We are excited to announce the Call for Abstracts for Shiny in Production 2024, to be held on 9th-10th October 2024 in Newcastle upon Tyne, UK. Read on for more details on how to submit your work.

Published: March 19, 2024.
SatRdays London is fast approaching and we wouldn't be able to put it on without the support of our sponsors!

Published: February 29, 2024.
Conferences present a great opportunity to meet other professionals working in your field and lay the foundations for future collaborations. But what should you do if the idea of meeting new people puts you well out of your comfort zone?

Published: February 27, 2024.
SatRdays London is fast approaching and we are happy to announce our full lineup of speakers for the event! Read on for more info. If you want to join the fun, head over to the conference website to sign up!

Published: February 15, 2024.
A very quick introduction to the new-look blog and tags pages and the brand new author pages.

Published: November 28, 2023.
All of our public training courses for the first half of 2024 are now available to book! Head over to the public courses page on our website to book in and start building your programming skills in the new year! In this blog post, we provide a list of all of our upcoming courses with a description, upcoming dates, course level and a link to the page to find out more!

Published: November 16, 2023.
Hey Barbie! I mean ... hey Python user! Have you ever wished that customising your Python environment could be as easy as trying different outfits on your Barbie? Well turns out it is! With virtual environments, you can create isolated Python projects with different dependencies and versions. Read our Barbie-themed guide to get started!

Published: November 14, 2023.
SatRdays is returning to London in April 2024! We're excited to welcome you to Bush House again next year. Want to get even more involved? Read on to find out how you can submit an abstract for a talk!

Published: October 5, 2023.
Python package managers are essential tools that help developers install, manage, and update external libraries or packages used in Python projects. These packages can contain reusable code, modules, and functions developed by other programmers, making it easier for developers to build applications without reinventing the wheel.

Published: September 28, 2023.
There's only two weeks left to go until Shiny in Production 2023! The events team are hard at work getting things ready for the day, and we wanted to take this opportunity to say a huge thank you to our event sponsors!

Published: September 21, 2023.
Jupyter notebooks are a popular tool for data scientists using Python. They allow us to mix together plain text (formatted as Markdown) with Python code. In this post, we will show you how to produce reproducible PDF and HTML reports from a Jupyter notebook using Quarto.

Published: September 14, 2023.
Our bags are packed, flights are booked, and we're ready to head stateside for posit::conf(2023). We're excited to be sponsoring the event this year, as well as presenting a few talks ourselves.

Published: September 7, 2023.
We are pleased to announce the full line-up for this year's Shiny in Production conference! In this blog post, we've pulled together all of the talk abstracts and speaker bios, to give you a full view of what to expect!

Published: August 29, 2023.
The Royal Statistical Society International conference is next week and Jumping Rivers are exhibiting at the conference, as well as delivering workshops and talks. The draft program can now be viewed online, so we wanted to let you know where you can find us at the event and some of the other sessions we are looking forward to.

Published: July 4, 2023.
Embark on your programming odyssey with our extensive range of courses! Never written a line of code in your life? No stress - we offer a mix of introductory courses for beginners as well as more advanced courses for those looking to expand their knowledge further.

Published: June 6, 2023.
This summer, we have public courses to take you all the way from the very basics of R, through to using R for statistical modelling, with some data wrangling and intermediate programming in between. Wherever you are on your R journey, take a look at our upcoming courses to see if we can help you on your way.

Published: May 2, 2023.
It's been just over a year since we introduced the world to diffify, our app for comparing package releases. To celebrate reaching this milestone, we're pleased to announce that an "anniversary update" has just gone live! Read on to learn about the latest changes and some exciting plans in the works…

Published: April 11, 2023.
We’re delighted to announce that we’ve been named a Finalist in the British Data Awards 2023. Read on to find out more about the awards, and the categories in which we are finalists!

Published: March 7, 2023.
SatRdays London is fast approaching, and we are happy to announce our full lineup of speakers for the event! Read on for more info. If you want to join the fun, head over to the conference website to sign up!

Published: February 2, 2023.
As data scientists we often need to communicate conclusions drawn from data. Additionally, as more data is collected, our reports invariably need updating. In this blog post we will look at how Quarto allows us to weave together text and Python code to generate automated reports.

Published: January 24, 2023.
At Jumping Rivers we're all about getting involved in the R community! As such, we host multiple events throughout the year. Read on for information about what we have planned so far for 2023!

Published: December 20, 2022.
If you're thinking of picking up a new skill in the new year, take a look at our upcoming public training courses! We have plenty of introductory courses coming up, both online and in-person, so you can hit the ground running after the holidays!

Published: December 6, 2022.
Over the last two weeks, we have been releasing the recordings of the talks from our Shiny in Production conference! Read on to take a look for yourself!

Published: December 1, 2022.
Data science and data engineering are incredibly cognitively demanding professions. As data professionals, we are required to leverage both our analytical/engineering skills and our interpersonal skills to be effective contributors within our organisations. In this blog, we discuss why this combination could reasonably count as an occupational hazard.

Published: November 15, 2022.
We are excited to finally release Python content on Diffify! You can now perform version comparisons for 1600 popular PyPI packages. Read on to learn about the new content, and our plans to expand this as we look to the future.

Published: November 10, 2022.
When creating graphs for a report or publication we usually want to ensure they follow a certain style. In this blog post we will look at formatting and colourmap customisation in the popular Matplotlib library.
Published: November 3, 2022.
The arrival of Shiny for Python was announced at the RStudio Conference a few weeks ago. In this tutorial I will take you through how I created a simple Shiny for Python dashboard, with no experience using the framework in R.

Published: October 18, 2022.
Here at Jumping Rivers we like to keep our courses up to date so we can bring you training on the latest tools and technologies. To this end, we have recently added two new courses to our listing!

Published: October 6, 2022.
Have you ever inherited a pile of messy code? Or perhaps you wrote some code a long time ago and it needs some TLC? Here are our tips for refactoring messy code.

Published: September 29, 2022.
Unit testing is an integral part of creating robust applications and codebases. Continuing the API as a package series we explore how you might set up unit tests with {testthat} for your API service.

Published: September 22, 2022.
Logging is crucial to understanding what's going on with an application as it runs. There are some good solutions to logging of R shiny applications but less so for plumber applications. Continuing the API as a package series we examine how you might add some automatic logging to your API service written in R using plumber and the logger package.

Published: September 20, 2022.
It will come as no great surprise that here at Jumping Rivers, we are huge advocates for learning data skills. There are many benefits to learning at least some basic data skills, even if you don't work explicitly with data.

Published: September 15, 2022.
Inspired by opinionated packages on {shiny} app development such as {golem} and {leprechaun}, Jumping Rivers adopted a similar pattern for producing a {plumber} API as a package for one of our client projects. This is one of a series of blog posts discussing the general structure of said package.

Published: September 8, 2022.
In this installment of our series on deploying to RStudio Connect we take a look at Streamlit. Streamlit enables quick and easy creation of web applications for machine learning and data science. We will go through a simple app and how to deploy it.

Published: September 1, 2022.
Next up in our blog post series on deploying Python APIs to RStudio Connect is FastAPI. FastAPI is a high-performance web framework for building APIs with Python. Read on to see how you can deploy your FastAPI apps with RStudio Connect!

Published: August 25, 2022.
RStudio Connect (soon to be Posit Connect) is a platform that provides the ability to deploy and share R applications and reports. However, it is not just for R developers (hence the name change). RStudio Connect also supports many Python applications, including Flask. In this blog we will look at how to deploy a Flask app to RStudio Connect.

Published: August 23, 2022.
RStudio conf 2022 had some exciting reveals. Certainly one of the most interesting releases was that of shiny, the excellent web application development framework known in the R community, getting a Python release. Here we will take a first look at creating a simple application.
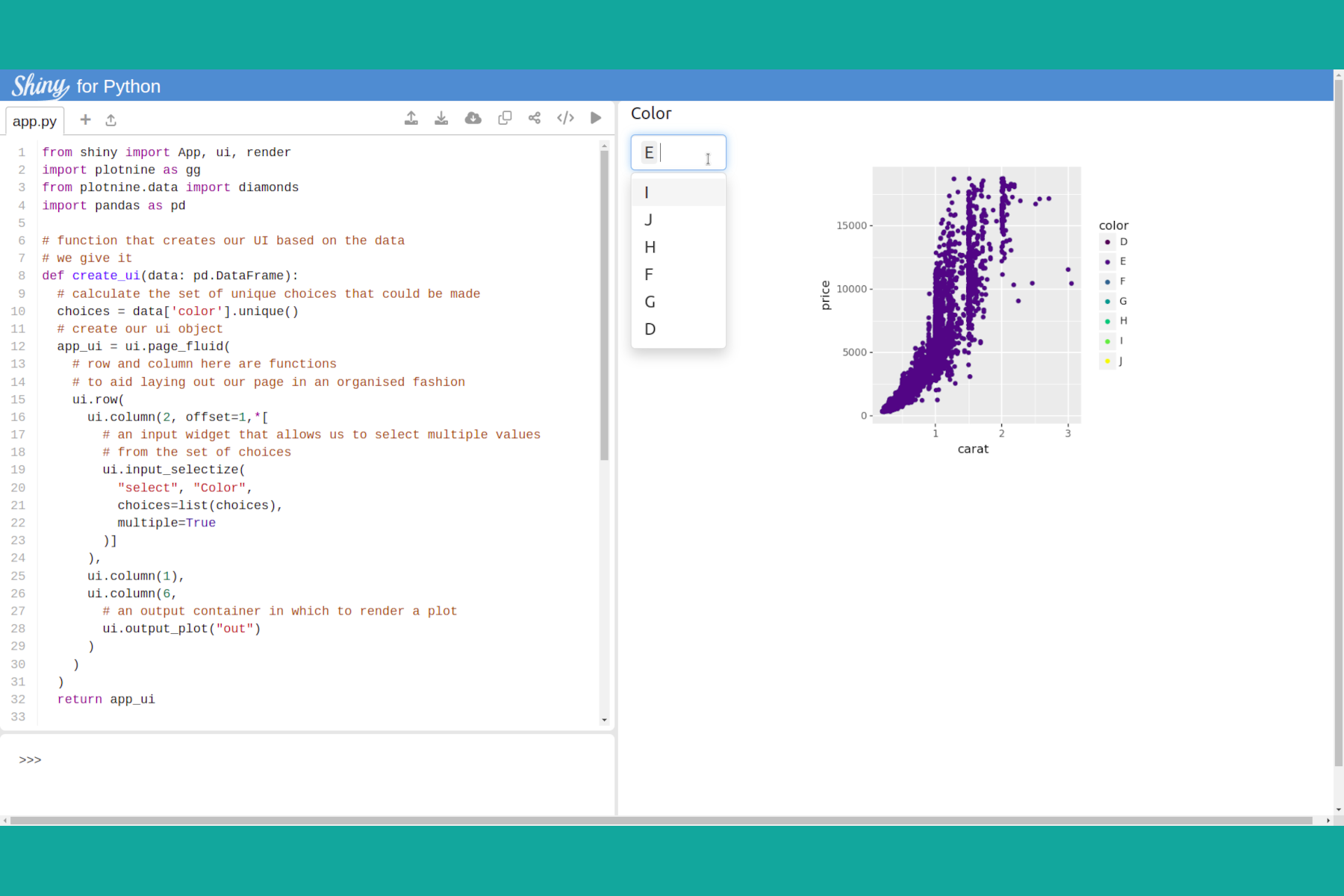
Published: August 11, 2022.
July 25 - 28 2022 saw thousands of people attend rstudio::conf(2022) from all over the world, including a few of us from Jumping Rivers. Here's a recap of the big news, and a few of our personal highlights from the conference!

Published: August 9, 2022.
What a few months it's been for Diffify, our new app for comparing package releases! We’ve been delighted with the enthusiastic response and quick adoption by the R community. Read on to learn about just some of many updates we’ve made to the app since launch day, and how we are actively addressing your feedback as we look to the future.

Published: July 12, 2022.
At Jumping Rivers, we love data science! Surprised? Didn't think so ... But, did you know that as well as providing training and consultancy, we also like to get involved with the data science community!

Published: June 28, 2022.
If you're based in the North East of England and you're looking for a place to discuss all things data science with like-minded people, then you might want to check out the North East Data Scientist (NEDS) Meetups!

Published: June 9, 2022.
H2O.ai is a company which develops products for easy, scalable, machine learning and artificial intelligence. This post will talk through who H2O.ai are and what software they provide for your machine learning needs.

Published: June 7, 2022.
The trainers here at Jumping Rivers have been busy developing a host of new courses for your programming pleasure! We have recently developed several new courses, which are now available to view on our course list.

Published: May 31, 2022.
Complex software bugs are often difficult to reproduce. Unfortunately, without this reproducibility it can be hard to get help and input from others. In this post we discuss a particularly nasty bug we encountered and how we made it reproducible.
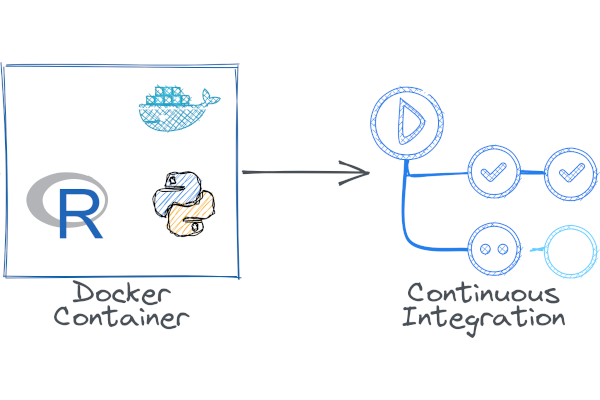
Published: May 26, 2022.
Have you ever wished your code could be as stylish as you? Linting is a process which helps ensure the format and style of your code adheres to best coding practices. Read on to learn about linters and auto-formatters, and start adding some PEP to your Python!

Published: January 25, 2022.
R 4.0 was released almost two years ago. However, the majority of R users didn't immediately adopt the new version due to obvious constraints when updating software. The consequence is that many of the new and useful features are forgotten about. This post highlights the features as we've moved to R 4.0.
Published: December 21, 2021.
Creating 30 maps for the 30 Day Map Challenge in November 2021 was indeed a challenge, but over the course of the month I developed a process for approaching the problem. This blog post will focus on the thought process behind creating maps rather than the technical aspects of writing the code.
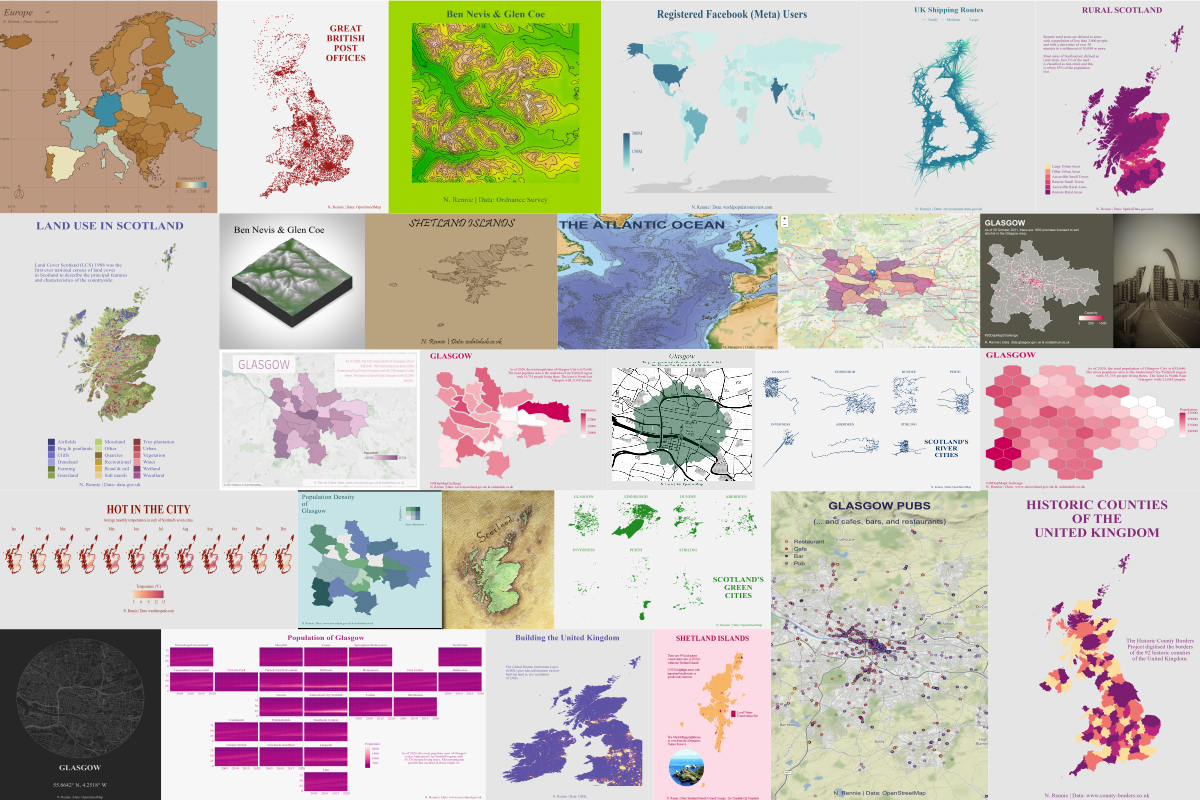
Published: December 15, 2021.
In line with the continuous growth at Jumping Rivers, we are looking to expand our team of dedicated professionals working in our teams. If you are enthusiastic and keen to develop your skills in cutting edge data science disciplines or infrastructure please read on!

Published: October 22, 2021.
Our annual training review is back! Like many other training providers, we had to pivot to online learning in 2020, which brought with it challenges but also new opportunities. The review will show you what the year looked like for our trainers and training course attendees, including which trainer taught the most courses!

Published: October 19, 2021.
In 2020, GitHub took the correct decision to change the default branch from master to main. For single, independent repositories, this is relatively straightforward. But moving groups or organisations is more complex and requires planning.

Published: June 1, 2021.
In line with the continuous growth at Jumping Rivers, we are looking to expand our team of dedicated professionals working in our teams. If you are enthusiatic and keen to develop your skills in cutting edge data science discliplines or infrastructure please read on!

Published: May 18, 2021.
Good news! We have updated our public course page with our new programme of courses, being delivered between May and November. Early bird offers & academic discounts currently available.

Published: October 13, 2020.
Don’t we all miss 2019 (blame Covid for the long delay in this post). The days of going to work and seeing your work colleagues face to face - and for some of you, attending one of our on-site training courses! 2019 was a great year for us.

Published: August 28, 2020.
One of our main roles at Jumping Rivers is to set-up and provide ongoing maintenance to R, Python and RStudio infrastructure. This typically involves ensuring software is up-to-date and making sure everything is running smoothly. The {oysteR} package is an R interface to the OSS Index that allows users to scan their installed R packages.
